Shuttle Launchpad #2: Structs and Enums
Welcome to the second issue of Shuttle Launchpad. We learned about how to get started with Cargo and Rust in the first issue, now we're working through our first real web application! The focus of today's issue: Structs and Enums!
Is this your first issue of Launchpad?, check out the Archive on www.shuttle.dev.
A Podcast Application.
We want to create a podcast website. The root gives an overview of a list of episodes, the episode page shows the title, description, and a link to the audio file.
To get the necessary podcast information, we use the RSS feed from your favorite podcast show!
We will deploy the application on Shuttle. This issue assumes that you brushed up your skills on Cargo from issue 1, where we also installed the Shuttle CLI tools using cargo install cargo-shuttle.
Let's create a new project.
$ mkdir podcast-app
$ cd podcast-app
$ cargo shuttle init
Make sure to select axum and pick a nice name for your app! Next, add a few dependencies to your Cargo.toml:
reqwest = "0.11.18"
xml = "0.8.10"
anyhow = "1.0.71"
In this issue, we want to learn how to define structs and enums. We will use them to parse the XML feed from the podcast. Structs are compound data types that can hold multiple values of different types. Enums are types that can have a fixed set of values, called variants.
To represent our podcast items, we define a new struct called Podcast with three fields: title, description, and audio_file. The audio_file is optional, while the RSS feed requires title and description, the audio file might not always be available, which is pretty bad for a podcast, isn't it? We use the Option type to represent this.
The Option type is an enum with two variants: Some and None. The Some variant wraps a value, while None represents the absence of a value. With that type, Rust effectively avoids having null or undefined values. It also requires you to explicitly check for each variant, which is a good thing, because it forces you to think about the absence of a value.
struct Podcast {
title: String,
description: String,
audio_file: Option<String>,
}
In Rust, you can attach methods to structs. We use this to define a constructor for our Podcast struct. The new method returns a new instance of Podcast with empty fields. The audio file is not set, this is why we set it to None.
The Self type refers to the type of the current struct. In our case, Self is Podcast.
impl Podcast {
fn new() -> Self {
Self {
title: String::new(),
description: String::new(),
audio_file: None,
}
}
}
Alright! Podcast feeds are RSS feeds, which means they exist as XML files. Hello? 1990s Java has called and wants to have their beloved file format back! Anyway, we define a function called read_podcasts_from_xml that takes a URL and returns a vector of Podcast items. The async keyword indicates that this function is asynchronous. We will learn more about asynchronous programming in a later issue.
We also need to import the Result type from the anyhow crate. The Result type is an enum that works very similarly to Option. It indicates the successful execution of a function or an error. We will learn more about Result and what it does in a later issue.
use anyhow::Result;
async fn read_podcasts_from_xml(url: &str) -> Result<Vec<Podcast>> {
let mut results = Vec::new();
// more code here!
Ok(results)
}
Add the following lines to the read_podcats_from_xml function. We use the reqwest crate to download the feed from the given URL. The reqwest crate is an HTTP client for Rust. The await keyword indicates that we work in an asynchronous context. The ? operator gets the value from the Result type or returns early if the Result is an error. Again, more on that in a later issue. With this line, we get the XML data as a string.
We also create a new EventReader from the xml crate. The EventReader is a parser for XML files. It takes a BufReader as input, which we create from the XML data. The BufReader is a buffered reader that reads the XML data in chunks. This is more efficient than reading the whole file at once.
use xml::EventReader;
use std::io::BufReader;
let data = reqwest::get(url).await?.text().await?;
let parser = EventReader::new(BufReader::new(data.as_bytes()));
Reading XMLs is a bit cumbersome. The XML parsing library also works with enums and tells us if we are inside an opening tag, closing tag, or within the contents of an item.
<rss version="2.0">
<channel>
<title>Podcast name</title>
<link>https://podcast.com</link>
<item>
<title>
<![CDATA[ ...]]>
</title>
<description>
<![CDATA[ ...]]>
</description>
<enclosure url="podcast.mp3" length="56525065" type="audio/mpeg"/>
</item>
...
</channel>
</rss>
We can extract the information we need from the XML by iterating over each item and reading the contents of title, description, and the url property of enclosure. Since the XML Parser has a different set of states, we create our own enum to keep track of the current state of the parser. We call it ParseState and define three variants: Start, InTitle, and InDescription.
enum ParseState {
Start,
InTitle,
InDescription,
}
We use a variable called state to keep track of the current state of the parser. We start with ParseState::Start, which indicates that we are at the beginning of the file. We also create a new Podcast instance.
let mut podcast = Podcast::new();
let mut state = ParseState::Start;
We loop over each event that the parser returns. The match keyword allows us to match the current event against a set of patterns. If the pattern matches, we execute the code in the corresponding branch.
If the Result is Ok, we match against the XmlEvent::StartElement variant. This variant indicates that we are inside an opening tag.
In the case of title and description, we set our own state variable to ParseState::InTitle and ParseState::InDescription. This allows us to keep track of the current state of the parser, so we can assign the contents (defined via the CData variants) to the correct field of the Podcast struct.
In the case of enclosure, we go through all its attributes and look for the url attribute. If we find it, we set the audio_file field of the Podcast struct to the value of the url attribute.
When we find a closing item tag, we add the parsed podcast episode to our vector, reset the state variable, and create a new Podcast instance.
use xml::reader::XmlEvent;
for event in parser {
match event {
Ok(XmlEvent::StartElement {
name, attributes, ..
}) => match name.local_name.as_str() {
"title" => state = ParseState::InTitle,
"description" => state = ParseState::InDescription,
"enclosure" => {
podcast.audio_file = attributes.into_iter().find_map(|attr| {
if attr.name.local_name == "url" {
Some(attr.value)
} else {
None
}
});
}
_ => {}
},
Ok(XmlEvent::CData(content)) => match state {
ParseState::InTitle => {
podcast.title = content;
state = ParseState::Start;
}
ParseState::InDescription => {
podcast.description = content;
state = ParseState::Start;
}
_ => {}
},
Ok(XmlEvent::EndElement { name }) => {
if name.local_name == "item" {
results.push(podcast);
podcast = Podcast::new();
state = ParseState::Start;
}
}
_ => {}
}
}
Note that all enum variants from XmlEvent contain data, this can be either a struct or a simple fiel (like in the case of CData). Enums not only indicate state, but they can carry associated data, making it easier for us get the right thing at the right time.
The .. syntax in the Ok(XmlEvent::StartElement { name, attributes, .. }) pattern is called a rest pattern. It allows us to ignore the rest of the fields in the struct. In this case, we are only interested in the name and attributes fields.
Fantastic, we successfully parsed an RSS feed and extracted the relevant information. Now it's time for the actual web application.
Rewrite the axum function and make sure you load the podcasts into a podcasts variable. We use the Arc type to share the podcasts between different executions of the same callback because they happen across threads.
We also define two routes, one for the root path / and one for every podcast episode. The root callback returns a list of all podcasts, while the podcast callback returns the HTML for a single podcast episode.
use std::sync::Arc;
use axum::{routing::get, Router};
type AppState = Arc<Vec<Podcast>>;
#[shuttle_runtime::main]
async fn axum() -> shuttle_axum::ShuttleAxum {
let podcasts =
read_podcasts_from_xml("https://url-to-your-favourite-podcast").await?;
let app_state = Arc::new(podcasts);
let router = Router::new()
.route("/", get(root))
.route("/:id", get(podcast))
.with_state(app_state);
Ok(router.into())
}
To display a single podcast, we need to create a string representation, containing the HTML with the title, description, and audio file. We can do this by implementing a to_html method on the Podcast struct.
We use the format! macro to create a string representation of the HTML. It's similar to println!, except that it returns a string instead of putting out the result to the command line. The r# syntax allows us to create a raw string, which means we don't have to escape the double quotes. We can use the {} syntax to interpolate the values of the title and description fields.
What you also see is the &self parameter. This is a reference to the current instance of the struct. We will talk about references in a future issue, but for now, all you need to know is that you can access the fields of the struct via self.[field_name].
impl Podcast {
// ...
fn to_html(&self) -> String {
format!(
r#"
My Podcast: {}
Title: {}
Description: {}
Audio: {}
"#,
self.title,
self.title,
self.description,
match self.audio_file {
Some(ref file) => file,
None => "No audio available",
}
)
}
}
NOTE: The newsletter screws up with the HTML representation, get the real code on Github
Notice that the audio_file might either exist or it doesn't. Rust requires us to handle every variant. We need to make sure that we handle the None case, otherwise, the compiler will complain.
Now that we can create string representations for Podcast, we implement the podcast handler. We add two extractors, one for the state and one for the path. The state extractor allows us to access the Arc<Vec<Podcast>> that we defined earlier. The path extractor allows us to access the id parameter from the path.
use axum::{extract::{State, Path}, response::{IntoResponse, Html}};
async fn podcast(
State(app_state): State<AppState>, Path(id): Path<usize>
) -> impl IntoResponse {
let podcast = app_state.get(id);
Html(match podcast {
Some(podcast) => podcast.to_html(),
None => "No podcast found".to_string(),
})
}
One beautiful thing about Axum extractors is that we don't need to make sure that the id is an actual number. By specifying the correct type in the handler function, Axum will only execute the handler if the id is a number. If it isn't, it will return an error! This is one of the things that I just love about Rust!
💡 Note for experienced developers: Not happy that I use new for an empty struct and to_html for an HTML representation? You are absolutely right! This is a challenge for you, make this code more idiomatic and closer to what we usually see in Rust. A few tips:
- Use the
Defaulttrait instead ofnew - Implement
IntoResponseforPodcastinstead of having its own method.
The root handler is a bit more complex. We need to iterate over all podcasts and create a list of links. We can do this by using the iter method on the Arc<Vec<Podcast>> and then using enumerate to get the index of each podcast. We then map each podcast to a string representation of a link. Finally, we join all links with a newline character.
async fn root(
State(app_state): State<AppState>
) -> impl IntoResponse {
let response = format!(
r#"
List of podcasts
{}
"#,
app_state
.iter()
.enumerate()
.map(|(id, podcast)| {
format!(r#"- /{}: {}"#, id, podcast.title)
})
.collect::<Vec<String>>()
.join("\n")
);
Html(response)
}
And that's about it! Now with all the code in place, we can run the application and see if it works.
$ cargo shuttle run
You should see something like this:
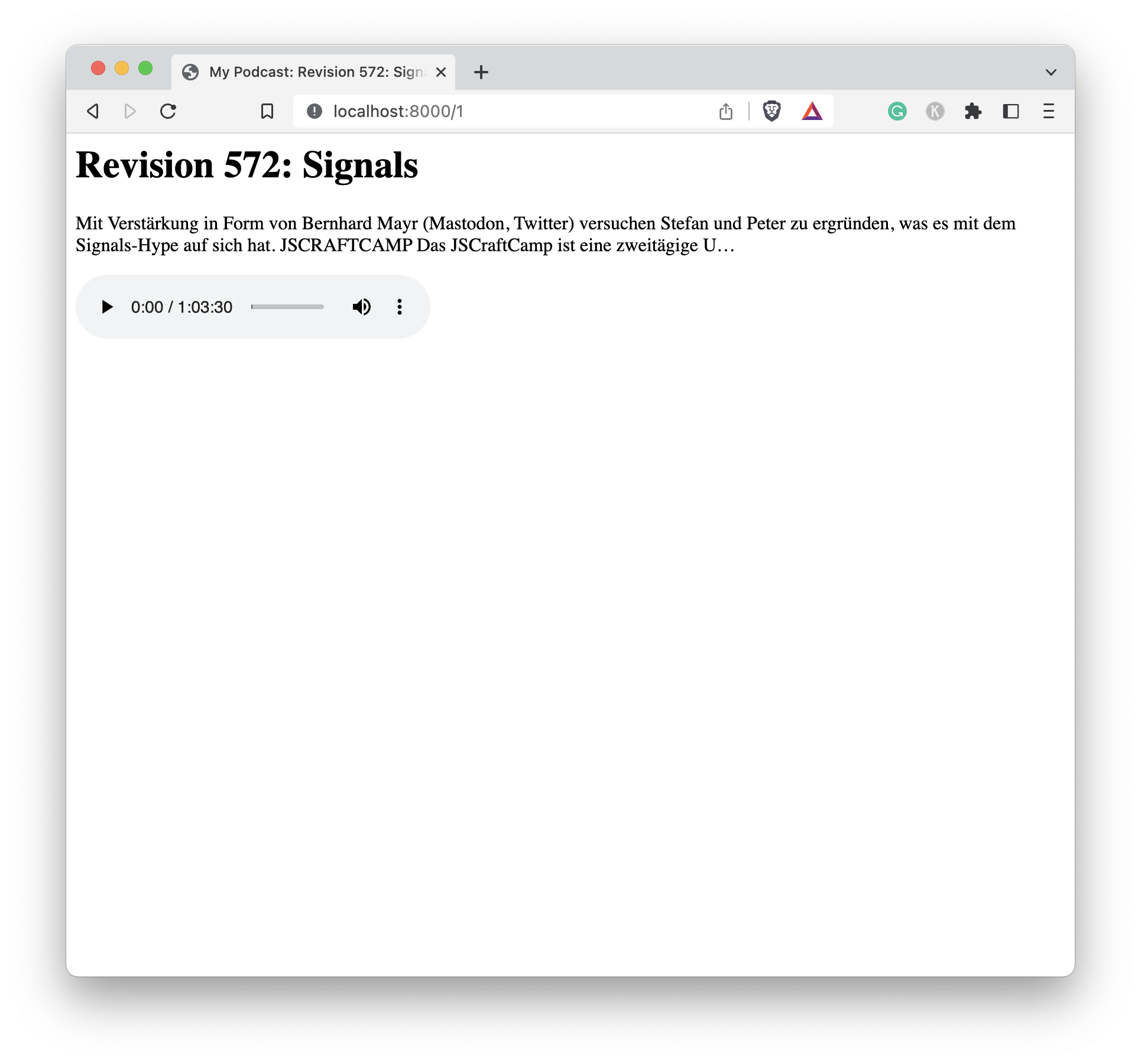
$ cargo shuttle deploy
And that's it! You just deployed a podcast web application to the cloud! 🎉
Let us quickly reiterate what we have learned:
- Structs are used to group related data together.
- Enums are used to define a type that can have multiple variants. Each variant can have different data associated with it.
- Both can have
implblocks, which allow us to define methods on the struct or enum. Optionis an enum that can either beSomeorNone. It is used to represent the absence of a value.
Btw. the app looks a little bleak, give it some beautiful styles! You can find the examples on GitHub.
Time for your feedback!
We want to tailor Shuttle Launchpad to your needs! Give us feedback on the most recent issue and your wishes here.
Join us!
Shuttle has a very active community. Join us on Discord, star us on GitHub, follow us on Twitter, and watch out for video content on YouTube.
If you have any questions regarding Launchpad, join the #launchpad channel on Shuttle's Discord.
Links, Videos, Tutorials
Web-based Services in Rust: Stefan is giving a three-day workshop in July, where you learn more about advanced web applications in Rust. Tickets are 250 EUR early bird!
Shuttle AI: We've just opened up the waitlist for Shuttle AI, a tool that allows you to build, validate & deploy an app, from a single prompt!
Building a semantic search using Qdrant and Shuttle: A three-hour webinar where Stefan writes a semantic search from scratch, including the use of LLMs.
More about the Option enum: Check out the official doc for the Option enum!
Launchpad Examples: Check out all Launchpad Examples on GitHub.
Bye!
That's it for today. Next time, we implement a real application together. Get in touch with us and let us know what you want to see!